最近开始做一些MLIR的工作,所以开始学习MLIR的知识。这篇笔记是对MLIR的初步印象,并不深入,适合想初步了解MLIR是什么的同学阅读,后面会继续分享MLIR的一些项目。这里要大力感谢中科院的法斯特豪斯(知乎ID)同学先前的一些分享,给了我入门MLIR的方向。
0x2. 什么是IR?¶IR即中间表示(Intermediate Representation),可以看作是一种中介的数据格式,便于模型在框架间转换。在深度学习中可以表示计算图的数据结构就可以称作一种IR,例如ONNX,TorchScript,TVM Relay等等。这里举几个例子介绍一下:
首先,ONNX是微软和FaceBook提出的一种IR,他持有了一套标准化算子格式。无论你使用哪种深度学习框架(Pytorch,TensorFlow,OneFlow)都可以将计算图转换成ONNX进行存储。然后各个部署框架只需要支持ONNX模型格式就可以简单的部署各个框架训练的模型了,解决了各个框架之间模型互转的复杂问题。
但ONNX设计没有考虑到一个问题,那就是各个框架的算子功能和实现并不是统一的。ONNX要支持所有框架所有版本的算子实现是不现实的,目前ONNX的算子版本已经有10代以上,这让用户非常痛苦。IR可以类比为计算机架构的指令集,但我们是肯定不能接受指令集频繁改动的。另外ONNX有一些控制流的算子如If,但支持得也很有限。
其次,TorchScript是Pytorch推出的一种IR,它是用来解决动态图模式执行代码速度太慢的问题。因为动态图模式在每次执行计算时都需要重新构造计算图(define by run),使得性能和可移植性都比较差。为了解决这个问题,Pytorch引入了即时编译(JIT)技术即TorchScript来解决这一问题。Pytorch早在1.0版本就引入了JIT技术并开放了C++ API,用户之后就可以使用Python编写的动态图代码训练模型然后利用JIT将模型(nn.Module)转换为语言无关的模型(TorchScript),使得C++ API可以方便的调用。并且TorchScript也很好的支持了控制流,即用户在Python层写的控制流可以在TorchScript模型中保存下来,是Pytorch主推的IR。
最后,Relay IR是一个函数式、可微的、静态的、针对机器学习的领域定制编程语言。Relay IR解决了普通DL框架不支持control flow(或者要借用python 的control flow,典型的比如TorchScript)以及dynamic shape的特点,使用lambda calculus作为基准IR。
Relay IR可以看成一门编程语言,在灵活性上比ONNX更强。但Relay IR并不是一个独立的IR,它和TVM相互耦合,这使得用户想使用Relay IR就需要基于TVM进行开发,这对一些用户来说是不可接受的。
这几个例子就是想要说明,深度学习中的IR只是一个深度学习框架,公司甚至是一个人定义的一种中介数据格式,它可以表示深度学习中的模型(由算子和数据构成)那么这种格式就是IR。
0x3. 为什么要引入MLIR?¶目前深度学习领域的IR数量众多,很难有一个IR可以统一其它的IR,这种百花齐放的局面就造成了一些困境。我认为中科院的法斯特豪斯同学B站视频举的例子非常好,建议大家去看一下。这里说下我的理解,以TensorFlow Graph为例,它可以直接被转换到TensorRT的IR,nGraph IR,CoreML IR,TensorFlow Lite IR来直接进行部署。或者TensorFlow Graph可以被转为XLA HLO,然后用XLA编译器来对其进行Graph级别的优化得到优化后的XLA HLO,这个XLA HLO被喂给XLA编译器的后端进行硬件绑定式优化和Codegen。在这个过程中主要存在两个问题。
第一,IR的数量太多,开源要维护这么多套IR,每种IR都有自己的图优化Pass,这些Pass可能实现的功能是一样的,但无法在两种不同的IR中直接迁移。假设深度学习模型对应的DAG一共有10种图层优化Pass,要是为每种IR都实现10种图层优化Pass,那工作量是巨大的。第二,如果出现了一种新的IR,开发者想把另外一种IR的图层优化Pass迁移过来,但由于这两种IR语法表示完全不同,除了借鉴优化Pass的思路之外,就丝毫不能从另外一种IR的Pass实现受益了,即互相迁移的难度比较大。此外,如果你想为一个IR添加一个Pass,难度也是不小的。举个例子你可以尝试为onnx添加一个图优化Pass,会发现这并不是一件简单的事,甚至需要我们去较为完整的学习ONNX源码。第三,在上面的例子中优化后的XLA HLO直接被喂给XLA编译器后端产生LLVM IR然后Codegen,这个跨度是非常大的。这里怎么理解呢?我想到了一个例子。以优化GEMM来看,我们第一天学会三重for循环写一个naive的矩阵乘程序,然后第二天你就要求我用汇编做一个优化程度比较高的矩阵乘法程序?那我肯定是一脸懵逼的,只能git clone了,当然是学不会的。但如果你缓和一些,让我第二天去了解并行,第三天去了解分块,再给几天学习一下SIMD,再给几个月学习下汇编,没准一年下来我就可以真正的用汇编优化一个矩阵乘法了。所以跨度太大最大的问题在于,我们这种新手玩家很难参与。我之前分享过TVM的Codegen流程,虽然看起来理清了Codegen的调用链,但让我现在自己去实现一个完整的Codegen流程,那我是很难做到的。【从零开始学深度学习编译器】九,TVM的CodeGen流程针对上面的问题,MLIR(Multi-Level Intermediate Representation)被提出。MLIR是由LLVM团队开发和维护的一套编译器基础设施,它强调工具链的可重用性和可扩展性。下面我们具体分析一下:
针对第一个问题和第二个问题,造成这些深度学习领域IR的优化Pass不能统一的原因就是因为它们没有一个统一的表示,互转的难度高。因此MLIR提出了Dialect,我们可以将其理解为各种IR需要学习的语言,一旦某种IR学会这种语言,就可以基于这种语言将其重写为MLIR。Dialect将所有IR都放在了同一个命名空间里面,分别对每个IR定义对应的产生式以及绑定对应的操作,从而生成MLIR模型。关于Dialect我们后面会细讲,这篇文章先提一下,它是MLIR的核心组件之一。
针对第三个问题,怎么解决IR跨度大的问题?MLIR通过Dialect抽象出了多种不同级别的MLIR,下面展示官方提供的一些MLIRIR抽象,我们可以看到Dialect是对某一类IR或者一些数据结构相关操作进行抽象,比如llvm dialect就是对LLVM IR的抽象,tensor dialect就是对Tensor这种数据结构和操作进行抽象:
除了这些,各种深度学习框架都在接入MLIR,比如TensorFlow,Pytorch,OneFlow以及ONNX等等,大家都能在github找到对应工程。
抽象了多个级别的IR好处是什么呢?这就要结合MLIR的编译流程来看,MLIR的编译流程大致如下:
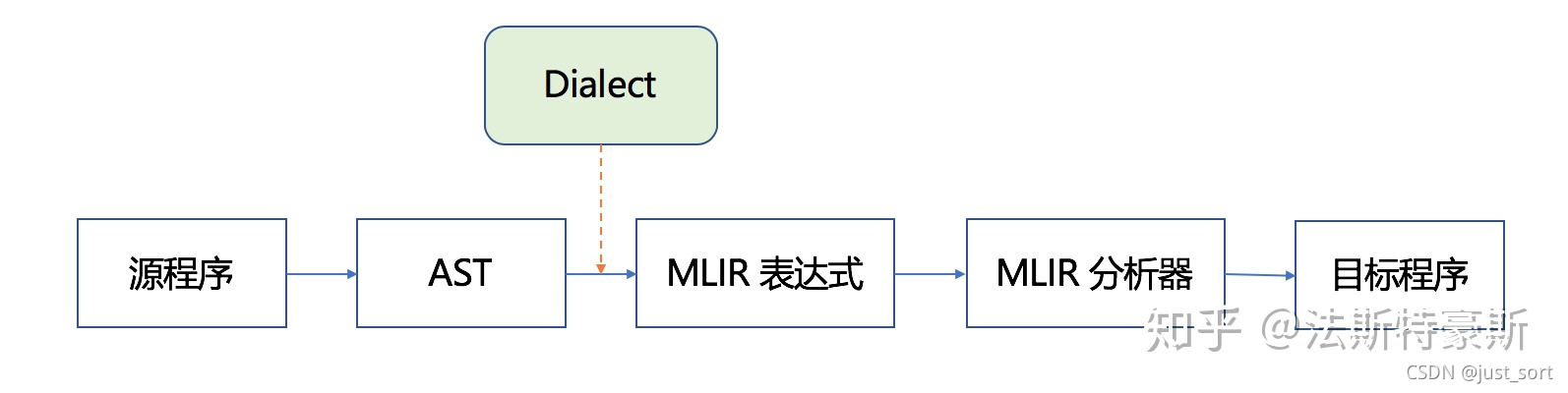
对于一个源程序,首先经过语法树分析,然后通过Dialect将其下降为MLIR表达式,再经MLIR分析器得到目标程序。注意这个目标程序不一定是可运行的程序。比如假设第一次的目标程序是C语言程序,那么它可以作为下一次编译流程的源程序,通过Dialect下降为LLVM MLIR。这个LLVM MLIR即可以被MLIR中的JIT执行,也可以通过Dialect继续下降,下降到三地址码IR对应的MLIR,再被MLIR分析器解析获得可执行的机器码。
因此MLIR这个多级别的下降过程就类似于我们刚才介绍的可以渐进式学习,解决了IR到之间跨度太大的问题。比如我们不熟悉LLVM IR之后的层次,没有关系,我们交给LLVM编译器,我们去完成前面那部分的Dialect实现就可以了。
0x4. 总结¶这篇文章简单聊了一下对MLIR的粗浅理解,欢迎大家批评指正。